[논문 리뷰] Exploring Multimodal Prompts For Unsupervised Continuous Anomaly Detection (ACM MM 2025)
논문리뷰
https://dl.acm.org/doi/pdf/10.1145/3746027.3755219
1. Introduction
- 산업 자동화의 급속한 발전으로 인해 이상 탐지는 산업 제조에서 없어서는 안 될 핵심 기술로 부상하였으며, 이는 제품 품질을 보장하는 데 중요한 역할을 함
- 전통적인 지도학습 기반 AD (Anomaly Detection)는 방대한 수동 레이블링 데이터가 필요하여 이는 비용과 시간이 많이 들기 때문에 레이블링되지 않은 데이터에서 이상을 식별하는 데 적합한 비지도 이상탐지 (Unsupervised Anomaly Detection, UAD) 방법이 주목받고 있음
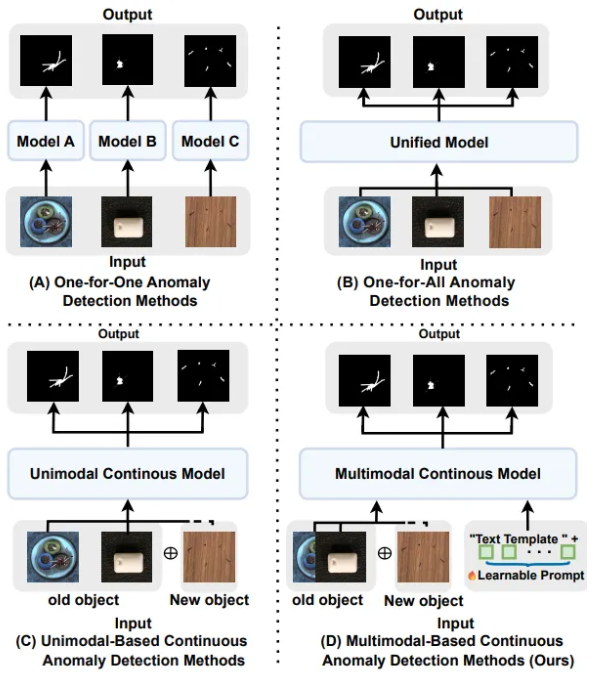
- 그러나 주류를 이루는 UAD 방법들의 경우 클래스별로 개별 모델을 학습하는 one-for-one 패러다임은 클래스 수가 증가함에 따라 계산 부담이 커지며, 다중 클래스에 대한 통일된 모델을 학습하는 방식은 빈번한 제품 변경 시 이전에 학습한 지식을 효과적으로 유지하지 못하고 치명적 망각 문제를 겪음
- 이러한 문제를 해결하기 위해 Continuous Learning이 효과적인 대안으로 제시되지만, 기존의 UCAD (Unsupervised Continuous Anomaly Detection) 연구들은 시각 정보에만 의존하여 복잡한 장면에서의 정상성 다양성을 포착하기 어렵고 성능 향상에 어려움이 있었음
- 따라서 본 논문에서는 Continuous Multimodal Prompt Memory Bank (CMPMB)를 제안하여, 텍스트 및 시각적 프롬프트를 융합한 CAD 방식을 구현하고자 함
2. Related Work
2.1. Multimodal Anomaly Detection
Multimodal cue learning은 cross-modal 특징 정렬 기술을 통해 이상 탐지 분야에서 중요한 발전을 이루었음
- SAA+ : Domain-expert multimodal 프롬프트를 통해 향상된 위치 정확도로 zero-shot segmentation을 수행하였음
- MMRD : 강력한 multi-class 이상 탐지를 위한 multimodal dedistillation 프레임워크를 제안
- IPDN : Multi-view semantic embedding을 통해 cross-modal 의미 모호성을 완화
→ Multimodal 정보가 이상 탐지 작업에서 효과적임을 보여주며, 본 논문이 multi-modal 프롬프트를 활용하는 배경을 제공
2.2. Unsupervised Anomaly Detection
비지도 이상탐지 기법은 주로 feature-embedding 방식과 reconstruction-based 방식으로 나뉨
Feature-Embedding 방식
- Teacher-student
- Single class classification
- Pre-trained feature space embedding
- Memory-enhanced architecture
Reconstruction-based 방식
- Autoencoders 기반
- GAN 기반
- ViT 기반
- Diffusion models 기반
→ 이 방식들은 주로 단일 모달 입력에 집중하여 특징 상호 보완을 위한 multi-modal 데이터의 잠재력을 간과하고 있음
2.3. Continuous Anomaly Detection
- CAD는 점진적인 지식 유지와 fine-grained 이상 세분화라는 과제에 직면
- 전통적인 방법들은 주로 클래스 내 이상을 다루며, 최신 연구인 UCAD는 structural contrastive learning을 도입했지만, 여전히 uni-modal 시각 입력에 한정
→ 이러한 한계를 극복하기 위해 본 논문은 multimodal 프롬프트 기반 CAD 프레임워크를 제안
3. Methodology
3.1. Overview
전체 모델 아키텍처는 아래와 같음
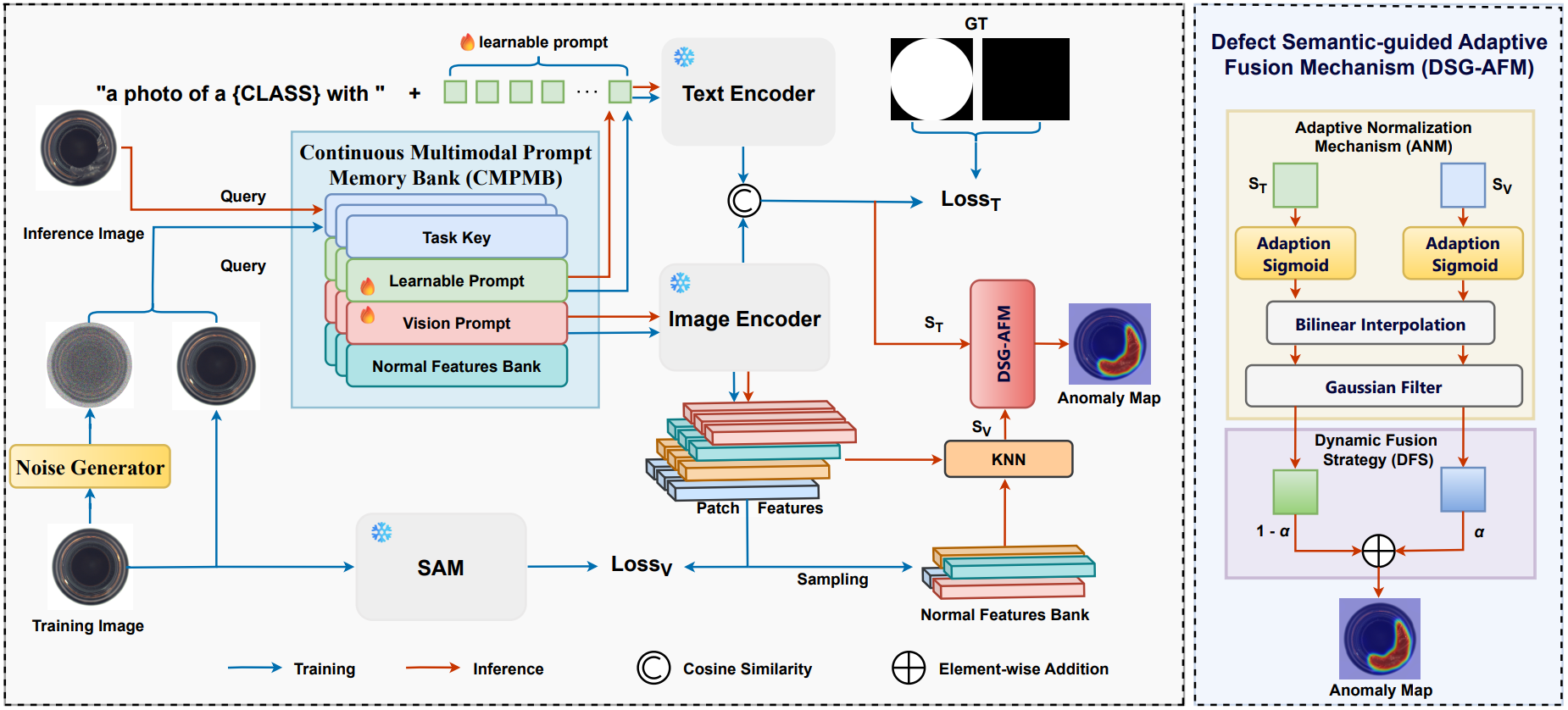
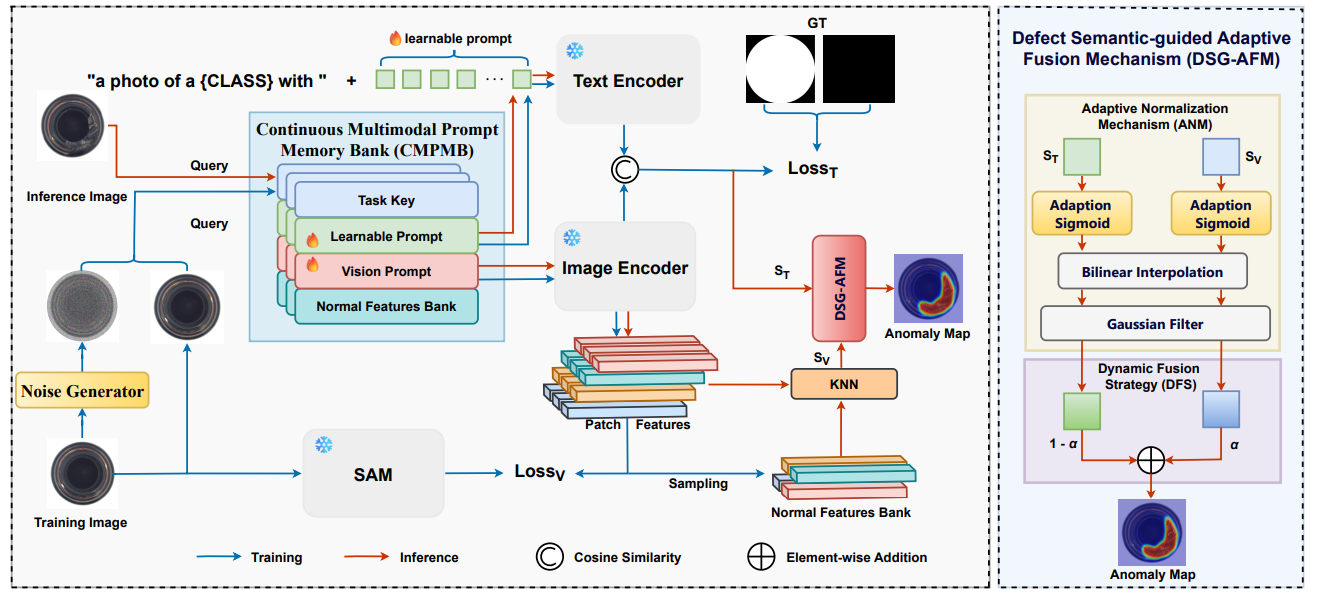
제안하는 모델은 Multimodal 프롬프트를 활용하며, 정상 특징 표현을 점진적으로 개선하고 지속적인 작업 지식 업데이트를 가능케하는 Continual Multimodal Prompt Memory Bank (CMPMB)를 핵심으로 함
3.2. Continuous Multimodal Prompt Memory Bank
산업 환경에서 태스크가 순차적으로 실행된다는 점을 고려하여, 본 논문은 학습 가능한 텍스트 프롬프트와 정제된 시각 프롬프트를 통합한 CMPMB를 구축하며, 이는 로 구성됨
-
, Task Identification
- Task adaptation phase에서 고정된 사전 학습 visual backbone 네트워크에서 추출된 patch-level feature에서 Farthest Point Sampling (FPS)을 사용하여 구성
- Task reasoning phase에서는 새로운 이미지 에 대해 추출된 key 와 Task identifier 간의 가장 높은 유사도를 계산하여 task identification 과정을 수행
-
, Normal Feature Library
- 정상 패턴을 저장하고 망각 문제를 완화하기 위함
- 사전 학습된 visual backbone 네트워크에 prompt를 사용하여 정상 특징을 추출한 후, coreset sampling을 통해 patch-level 특징을 압축하여 구성
-
, Learnable Text Prompt
-
CLIP의 멀티모달 정렬 프레임워크에서 영감을 받아 정상 샘플의 의미론적 분포를 인코딩
-
“a photo of a [CLASS] with [] 형식의 학습 가능한 프롬프트 템플릿 를 도입
-
는 학습 가능한 벡터들의 집합이며, 노이즈가 추가된 샘플을 사용하여 MSE 손실함수 를 통해 학습되며, 이는 수동 레이블링 없이 정상 패턴을 학습하도록 도움
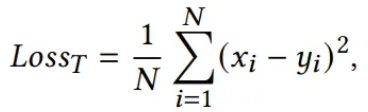
-
-
, Refined Visual Prompt
-
Task-aware visual prompt 는 개의 학습 가능한 벡터로 구성되며, prefix-tuning을 사용하여 사전 학습된 visual backbone 네트워크의 각 계층 입력 특징에 시각 프롬프트 를 통합하며, 이는 로 표현
-
해당 프롬프트는 아래 contrastive loss 식을 통해 학습됨
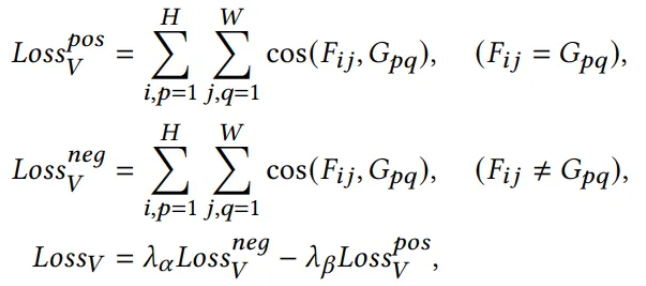
-
이는 SAM을 통해 추출한 zero-shot segmentation mask를 사용하여, 패치마다 같은 레이블에 속하는 패치는 인접한 공간에 놓이도록, 다른 레이블에 속하는 패치끼리는 먼 공간에 놓이도록 학습을 유도하며, 자세한 알고리즘은 아래와 같음
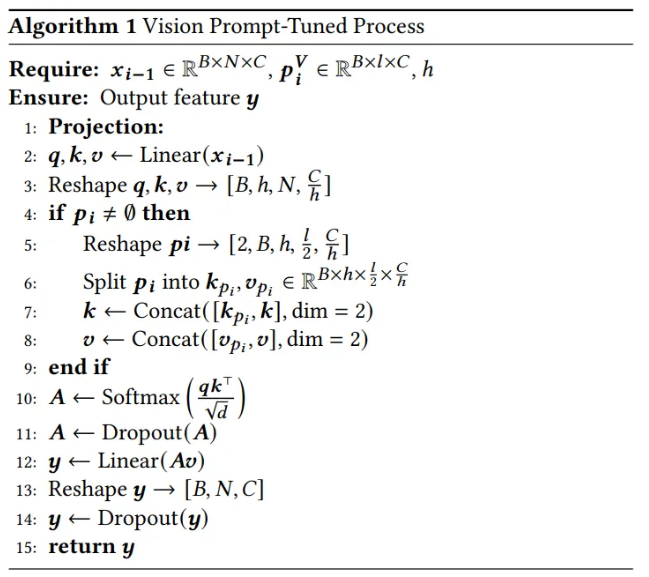
-
3.3. Adaptive Fusion Mechanism Based On Defect Semantic Guidance
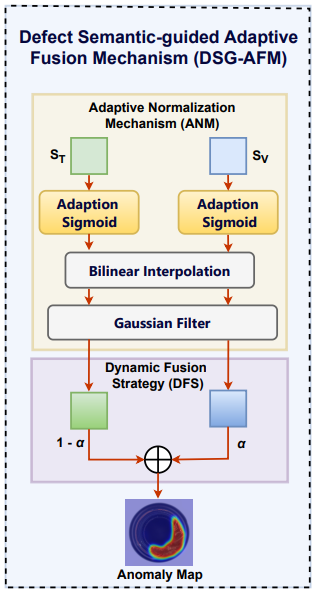
제안하는 모델이 다중 모달 정보를 효과적으로 융합하여 이상 탐지 성능을 극대화하고자 함. 이 메커니즘은 defect semantics의 지도를 받으며, Adaptive Normalization과 Dynamic Fusion 전략을 결합하여 강건하고 정확한 anomaly map을 생성
Two-branch Cooperative Reasoning
모델은 시각 정보와 텍스트 정보 처리를 위한 두 가지 branch를 가짐
- Visual Branch
- 사전 학습된 ViT backbone에서 이미지의 시각적 특징을 추출
- 이 특징들은 CMPMB에 저장된 와 비교되어 현재 이미지가 어떤 태스크에 속하는지 빠르게 파악
- 해당 태스크와 관련된 시각 프롬프트 가이드 모델을 통해 이미지 특징 를 얻음
- Normal feature library 에 저장된 정상 프로토타입 특징들과 patch-level에서 Nearest Neighbor Distance를 계산하여 예비 Visual Anomaly Score 를 얻음. 이는 이미지에서 시각적으로 정상 패턴과 다른 부분을 식별
- Text Branch
- CMPMB에 저장된 학습 가능한 텍스트 프롬프트와 이미지 특징을 기반으로 텍스트 인코더에서 의미론적 정보가 풍부한 텍스트 특징 을 얻음
- 이 와 visual branch에서 얻은 이미지 특징 간의 코사인 유사도를 계산하여 Text-guided Anomaly Score 을 생성. 이는 이미지 내용이 텍스트 프롬프트가 정의하는 “정상 의미론”과 얼마나 일치하는지 나타냄
Adaptive Normalization Mechanism, ANM
생성된 Anomaly Score ()는 그 자체로 사용할 경우 분포가 불안정할 수 있기에, ANM은 이 점수들을 동적으로 정규화하여 이상 탐지의 강건성을 높이고, 태스크마다 다른 데이터 분포에 더 잘 적응하도록 함
정규화에는 sigmoid 함수를 사용
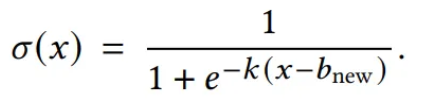
- 하이퍼파라미터 , 를 통해 sigmoid 함수의 기울기와 중심 위치를 조정하여 이상 점수를 동적으로 정규화하여 이상 점수를 최적화
- Greedy 탐색 전략을 사용하여 를 동시에 최적화하는 데 상당한 계산 부담이 주어지므로, 본 연구에서는 를 1.5의 고정값으로 사용하며, 의 경우 step 집합 을 정의하고, 각 학습 반복마다 validation set에서 가장 좋은 탐지 성능을 보이는 값을 선택
Dynamic Fusion Strategy, DFS
Visual Anomaly Score 와 Text-guided Anomaly Score 를 결합하여 최종 anomaly map을 생성
-
와 모두 bilinear interpolation을 통해 해상도의 anomaly score 로 업샘플링
-
최종 anomaly map 은 아래와 같이 계산
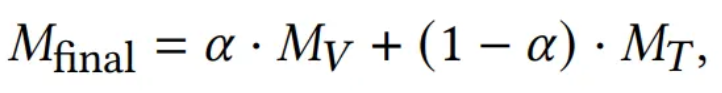
- 여기서 하이퍼파라미터 는 와 의 기여도를 조절하며, 일 때 최적의 성능을 보여주었음
4. Experiments
4.1. Experimental Setup
Datasets
- MVTec AD: 15가지 산업 제품의 정상 및 비정상 이미지를 포함
- VisA: 당시 가장 큰 실제 산업 이상 탐지 데이터셋
Competing Methods and Baselines
- 전통적인 AD 방법: CFA, CS-Flow, CutPaste, DRAEM, FastFlow, FAVAE, PaDiM, PatchCore, RD4AD, SPADE, STPM, SimpleNet, UniAD 등을 비교에 사용
- CAD 벤치마크: UCAD
- Replay-based: PatchCore와 UniAD는 메모리뱅크를 사용하는 PatchCore와 통합 패러다임의 UniAD의 강화 버전으로, replay 기반 CAD를 시뮬레이션하도록 설계. 이는 본 논문이 replay 메커니즘 없이도 성능 우위를 보임을 강조하기 위함
Evaluation Metrics
- Image-level AUROC
- Pixel-level AUPR
- Forgetting Measure
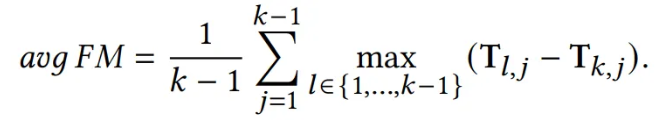
4.2. Comparison With Other Methods
Quantitative Analysis
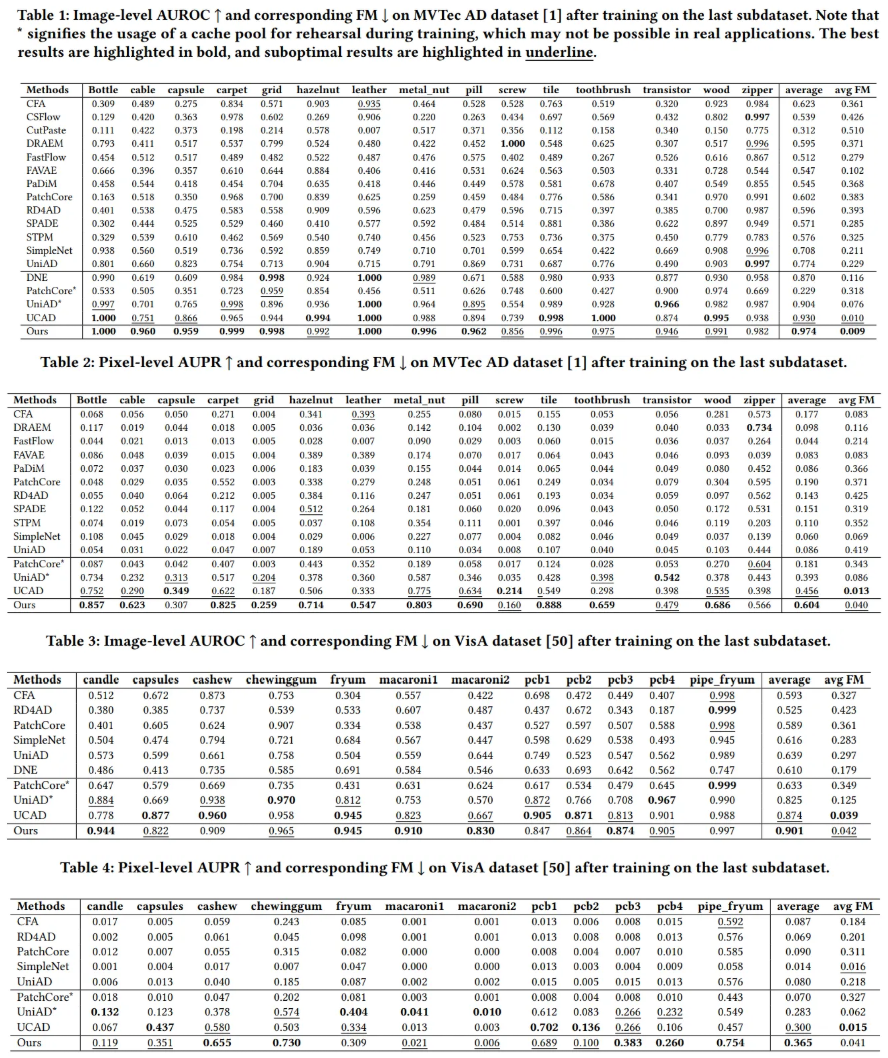
- MVTec AD, VisA 데이터셋의 image-level, pixel-level 모두에서 전반적으로 모든 비교 모델 중 가장 우수한 성능을 보여주었음
- 본 논문의 모델은 낮은 망각률을 유지했으며, 이는 CMPMB가 replay 메커니즘 없이도 망각 문제를 완화하며, 이전 학습된 지식을 잘 유지함을 의미
- 기존 UCAD가 시각 정보에만 의존하여 성능 한계가 있었던 반면, 본 논문은 텍스트 정보를 통합함으로써 탐지 및 세분화 정확도를 크게 향상시키며, 이는 multimodal 정보가 복잡한 장면에서 정상성을 더 풍부하게 표현하는 데 결정적인 역할을 했음을 시사
Qualitative Results

- 실제 이미지에 대해 모델이 생성한 anomaly map을 시각적으로 보여주며, 이전 SOTA인 UCAD와의 비교를 통해 제안 방법의 우수성을 직관적으로 보여줌
4.3. Ablation Study
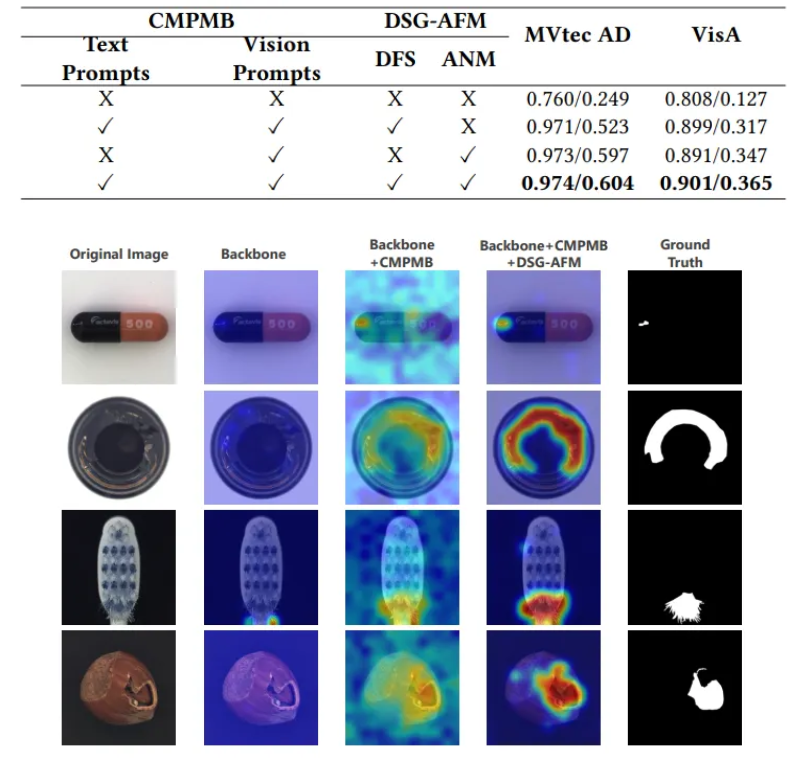
- 제안하는 두 가지 핵심 모듈인 CMPMB와 DSG-AFM의 기여도를 평가
- CMPMB가 CAD 환경에서 이상 탐지 모델의 기반을 튼튼히 하고 성능을 향상시키며, DSG-AFM은 그 기반 위에 pixel-level의 정밀한 이상 세분화 능력을 더해 최종적으로 강력한 SOTA 성능을 달성함
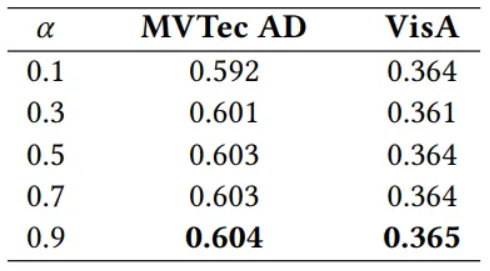
- DFS 모듈에서 와 의 가중치 균형을 조절하는 하이퍼파라미터 의 영향을 분석
- MVTec AD와 VisA 모두에서 일 때 pixel AUPR 성능이 가장 좋았으며, 이는 시각적 특징이 텍스트 특징보다 이상 세분화에 더 큰 기여를 하며, 텍스트는 주로 의미론적 컨텍스트 제공으로 시각 정보를 보완하는 역할을 한다는 것을 시사
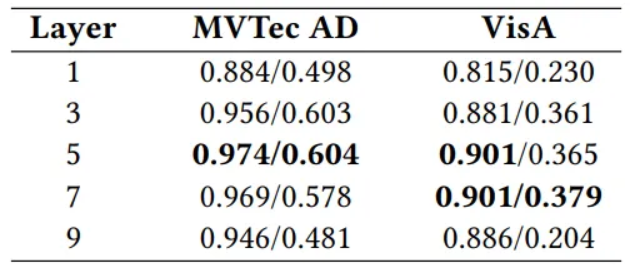
- 사전 학습된 ViT에서 어떤 계층의 특징을 사용하는 것이 가장 효과적인지 분석
- Layer 5의 특징을 사용했을 때 MVTec AD와 VisA 모두에서 가장 좋은 AUROC와 AUPR 성능을 보임
- Layer 5의 특징은 저수준의 시각 정보(경계, 질감)와 고수준의 의미론적 정보(객체 형태, 부품)를 균형 있게 포함하고 있어 이상 탐지에 가장 적합하다는 것을 의미
