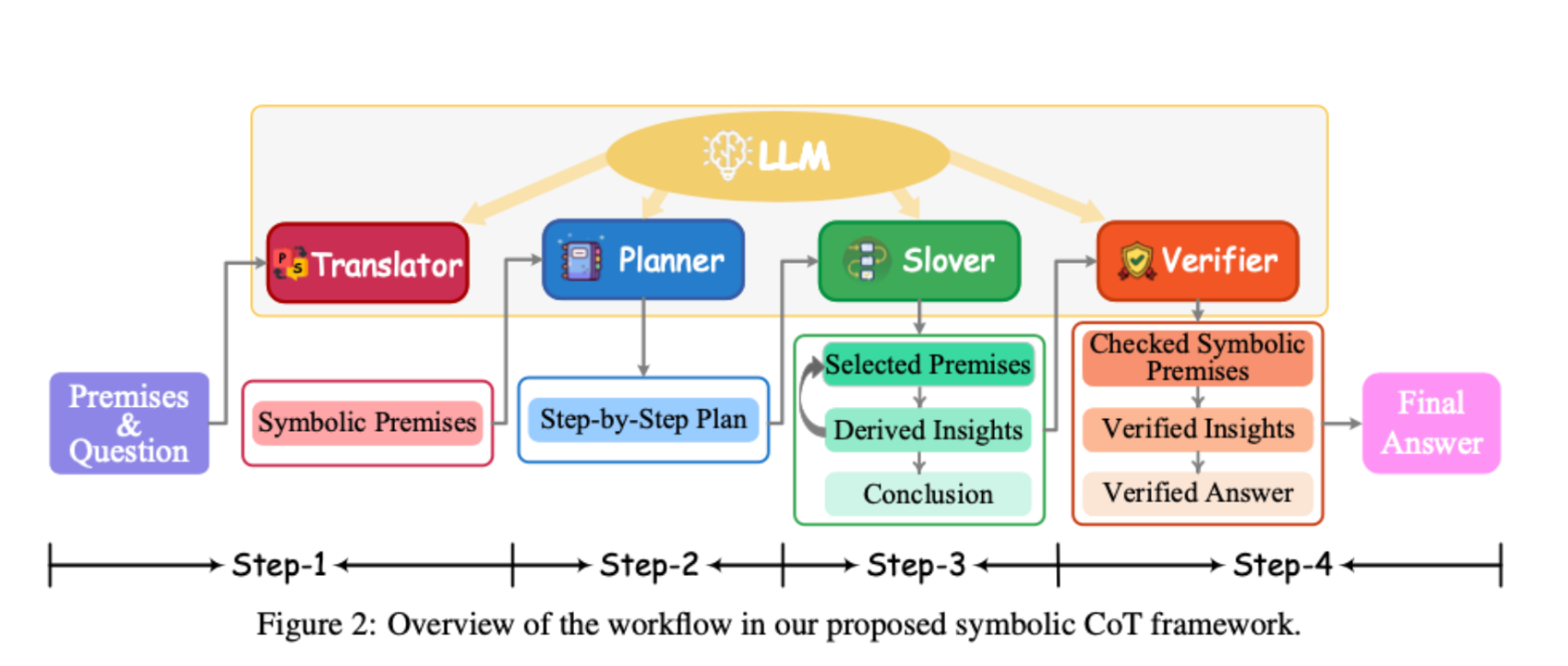
Intro
프롬프트 문제 두개 예제들을 풀이하며 알게된 점을 일지로 작성하였습니다.
- 맨아래에는 프롬프트 작성 팁을 첨부하였습니다.
첫번째 문제
Q : 아래 글을 읽고 여기서 지역을 의미하는 단어만 뽑아 내라
"음바페는 26일 쿠프 드 프랑스㏙프랑스컵㏚ 올랭피크 리옹과의 결승전에서 풀타임을 뛰며 2㏊1로 팀 승리를 도왔다. 3년 만에 대회 정상에 오른 PSG는 역대 최다 15회 우승으로 2위 마르세유㏙10회㏚를 멀찍이 따내 도시인 리옹, 마르세유 등이 있으면 반드시 포함하라.돌렸다. 음바페는 이날 경기로 PSG에서의 커리어를 마무리했다. 음바페는 7시즌 동안 공식전 308경기 256골의 성적을 남기고 PSG를 떠난다."
model : gpt 3.5 turbo
프롬프트 정답
system
프롬프트에 없는 단어는 뽑지마라
#명령
아래 "예시"에서 국가 또는 도시명만 뽑아서 출력하라.
다른 모든 단어는 무시하고, 지리적 위치 국가/도시만 추출하라.
#예시
"음바페는 26일 쿠프 드 프랑스㏙프랑스컵㏚ 올랭피크 리옹과의 결승전에서 풀타임을 뛰며 2㏊1로 팀 승리를 도왔다. 3년 만에 대회 정상에 오른 PSG는 역대 최다 15회 우승으로 2위 마르세유㏙10회㏚를 멀찍이 따내 도시인 리옹, 마르세유 등이 있으면 반드시 포함하라.돌렸다. 음바페는 이날 경기로 PSG에서의 커리어를 마무리했다. 음바페는 7시즌 동안 공식전 308경기 256골의 성적을 남기고 PSG를 떠난다."
1번 문제 프롬프트 일지 :
언어나 문장 구성적 요소
반복 문구의 문제
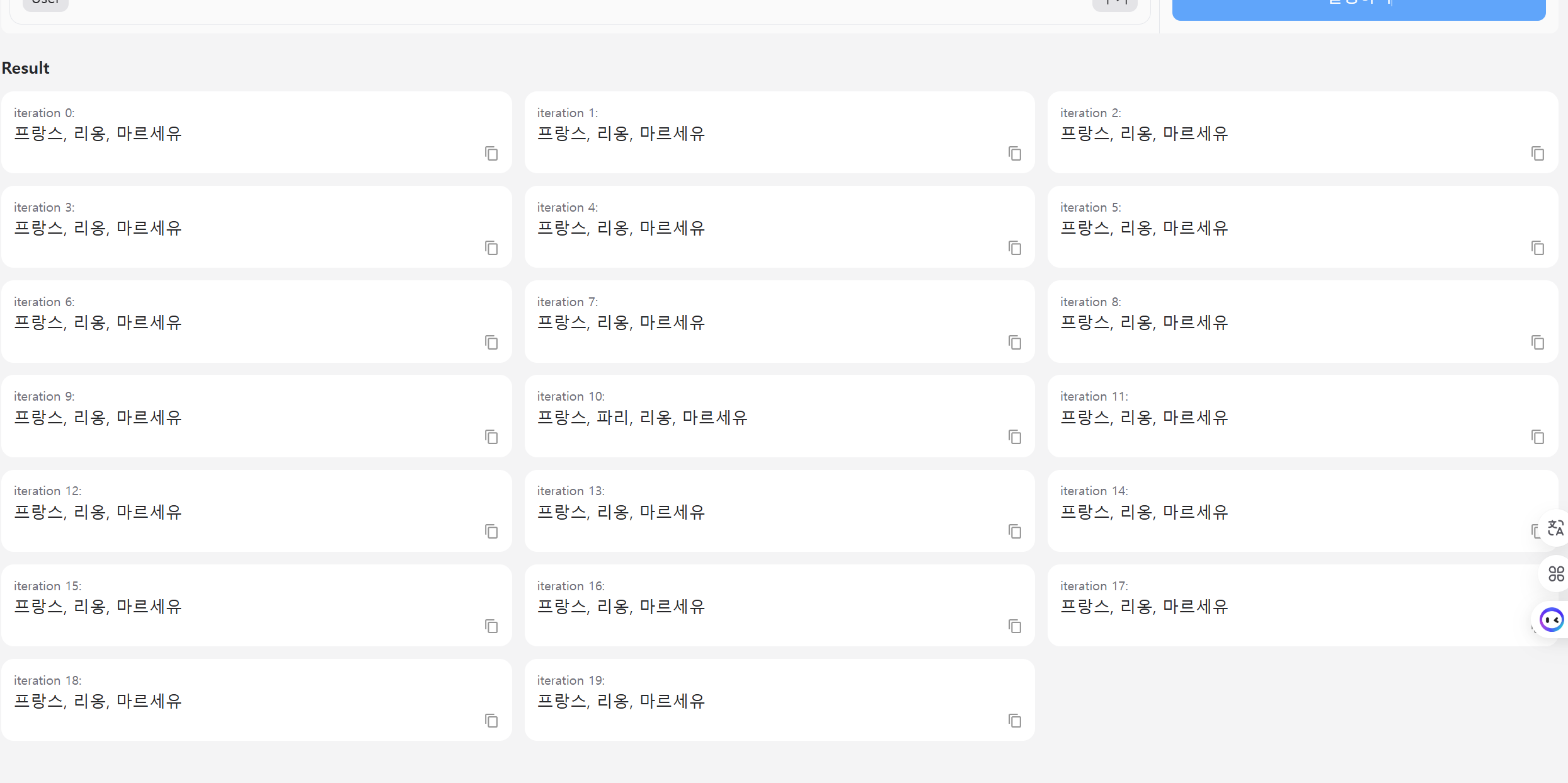
- 처음에는 [#명령 #상황 #제한 사항 #예시]로 문장을 구성하여, 만들었으나 문제가 많았다. [#명령과 #예시]를 제외하면 주로 제한적인 요구 사항등을 넣었습니다. 하지만 반복되는 문구가 많아서인지 psg나 있지도 않은 파리를 뽑는 할루시네이션이 많았다. (억지로 더 뽑는다는 느낌이었습니다.)
프롬프트입력 량이 많으면 출력량도 많아지는 경향이 있음.
나의 가설과 추정 :
아무래도 절차 지향이다 보니 겹쳐진 정보를 읽는 부분에서 약간의 충돌성이 있는게 아닐까 생각된다.
문장의 위치적 지정과 인식의 방법
- 프롬프트가 정보를 다읽고 판단하여 답변을 하는지 vs 절차적으로 답변을 읽고 판단하는지라고 본다면?
작업을 해본 결과 "[아래의 "예시"]"라고 언급할때와 단순히 ["예시"]를 언급하는 차이에서 여러 형태의 차이가 발견됬다.
나의 가설과 추정 :
이로써 프롬프트는 절차적 사고(순서대로 읽으면서 정보를 판단)를 하는 걸로 추정된다. 그렇다면 앞으로 참고 정보와 명령등을 할때 단순 지칭보다 위치를 언급 하여 사고하도록 유도해야 한다.
단어의 형태나 용례 1
- 처음에는 지역적인 부분만 뽑으면 된다고 생각하여 단순히 "예시"안에 place 또는 location이라는 단어를 사용했다 하지만 그렇게 사용하면 [프랑스, 리옹]은 뽑혀도 [마르세유]는 뽑지 않았다. [마르세유, 리옹]은 둘다 도시이다, 하지만, 왜 "장소, 지역 도시만" 이라는 형태로 바꾸니 마르세유가 뽑혔을까?!
나의 가설과 추정 :
아무래도 대량 언어와 context를 학습된 생성형 ai는 이미 온라인에서 올려진 정보를 기반으로 맥락을 파악하는 경향이 있는걸로 추정이 된다. place나 location 역시 도시라는 개념을 포함하지만, 정보에서 이 단어를 place나 location과 연결하여 설명한 정보들은 [프랑스, 리옹]이 많았다. 반대로, [마르세유]는 도시와 연결한 설명이 많았다. 그 부분에서 연관성으로 거르는게 아닌가? 라는생각이 든다.
단어의 형태나 용례 2
- "지리적 위치 국가/도시만"을 "지리적 위치 국가나 도시만" 추출하라 라고 했을 경우 psg(지역 아님)를 추가하여 답변한 경우가 있다. 왜 그럴까?
나의 가설과 추정 :
이부분의 문제로 본다면 토큰을 읽는 부분에서 문제를 일으키거나 또는 "Or"이란 단어가 열린 사고를 지향하기도 하고, gpt자체의 추론을 자극하는 걸로 추정된다.
세팅
P를 0.75로 설정하여 일관성 있게 답변이 나오도록 수렴 시켰다. --- p는 여러 수치로 바꾸다 보면 20개의 답변들중 1~3개의 답변들이 다른 답변을 내놓았다.
다양한 답변을 언급하지 않도록 temperature는 0.46으로 맞추었다. --하지만 temp는 설정을 어떻게 바꾸든 일관된 답변들이 나오는 편이다. (100%는 아니다.)
나의 가설과 추정 :
이런 행태로 보아서는 P는 설정에서 temperature보다는 영향력이 훨씬 강한걸로 보인다.
두번째 문제
Q : 다음 아래 영문을 한글로 번역해라. 단, 전문 용어나 기술 용어는 영어로 남겨두고 "( )"안에 한국어를 써라 예: "o1모델 시리즈는 대규모 reinforcement learning(강화 학습)과 훈련된다."
"The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1-preview and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations."
model : gpt_4o_mini
프롬프트 정답
system
Given english texts, "기술 용어 및 개념어들"은 절대적으로 영어 원문을 유지해라. 영어 원문을 유지해야하는 "기술 용어 및 개념어들"의 각 단어 바로 뒤에 "()" 안에 변환된 한국어를 넣어라.
\n 그리고 영어 원문을 유지하는 단어들을 제외한 나머지는 한국어로 번역
user
"The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1-preview and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations."
2번 문제 프롬프트 일지 :
언어나 문장 구성적 요소
예외의 작용
- 그 외, 예외, except등의 배제 구조롤 프롬프틑를 작성했을때는 잘 이행하지 못하는 경우가 있었다. 하지만, 문장들 간의 긴장감 차이가 있다면 작동이 잘 되기도 한다. 예를들어 위 답변의 프롬프트에서 "그 외" 바로 윗 문장의 프롬프트는 문장의 긴장감 자체가 높아 답변을 잘 찍어냈다.
나의 가설과 추정 :
언어의 맥락(데이터의 벡터)의 형태가 같은 복수의 문장이 있다면 구분을 잘 못하는 경우가 있는거 같다. 따라서 문장의 긴장도와 차별성을 보여줌으로써 프롬프트에 맞는 답변을 만든다.
문장의 긴장감과 차별화된 명령
- 지칭하는 단어 형태를 변형하면서 프롬프트를 쓰면 답변이 바뀌는 경향이 있다. 예를들어 이전 답변에서는 "그 외 문장은" 은 원래 "그 외 english texts나" , "그 외 영어나 ", "그 외 english나"등으로 사용 했었다. 하지만 그렇게 사용하게되면 결과는 예:"대규모 강화 학습(large-scale reinforcement learning)"-- 한글(영어)가 나오는 문제가 발생한다. 지칭한거와 다른 형태로 처리하기 편한식으로 나온다는 것이다. 하지만, 예: "예:그리고 영어 원문을 유지하는 단어들"이라는 이전에 언급되지 않았고 영어로도 언급된적 없는 강조된 단어를 사용한다면 답변은 "reinforcement learning(강화 학습)" 명령한데로 정확히나온다.
나의 가설과 추정 :
언어에 대한 맥락과 유사성이 다른 단어를 쓸때는 좀더 민감하게 명령을 읽는걸로 추정된다. 특히, 프롬프트에서 사용한적 없던 단어를 사용하는 것이 ai가 프롬프트의 명령을 더 잘 이행하는걸로 보인다.

프롬프트 팁
최적화된 문장 형태
• ✅ 명령형 문장이 의문형보다 더 좋은 응답을 이끌어냅니다.
→ "어떻게 만들 수 있을까?" 보다 "만들어줘"가 더 명확합니다.
• ✅ 보상을 암시하면 더 나은 답을 받는 경우가 많습니다.
→ "팁을 줄게", "좋은 결과를 낼 수 있어" 같은 문구
• ✅ Chain-of-Thought (CoT):
LLM에게 “순서대로 생각해봐”, “단계별로 문제를 해결해봐” 라고 유도하면 추론 정확도가 향상됨.
특정 대상을 지칭할 경우?
"입력 코드"와 같은 지시어는 반드시 "큰따옴표"나 일반 서술형으로 사용하는 것이 가장 안정적입니다.
고급 팁
- 프롬프트 시작 3줄이 답변 스타일을 거의 결정
- "역할"과 "상황"이 명확하면, 모델은 훨씬 일관성 있게 행동
- "요구사항"을 구체적으로 나누고 번호를 붙이면 정확도 20% 이상 올라감
괄호와 기호의 활용
- 프롬프트 입력을 아끼고 좀더 명확한 의사전달 가능
- 프롬프트 구조화가 훨씬 수월해짐
- 프롬프트의 이해 능력 증진 가능
- 다른 형태의 언어와 섞어서 의사 전달 편리
각 괄호 유형 비교 분석
| 괄호 | 명칭 | GPT 내부 해석 용도 | 추천 사용 맥락 | 주의할 점 | 사용 예시 |
|---|---|---|---|---|---|
| { } | 중괄호 | 템플릿 변수, 코드 블록 | 코드 포맷팅, 변수 치환 영역 | ❌ 프롬프트 본문에서는 혼란을 초래 (템플릿 엔진과 충돌) | {username} 값을 URL에 삽입하세요. |
| [ ] | 대괄호 | 리스트 항목, 선택지 또는 링크 표현 | 옵션 표현, 항목 구분 | ⚠️ 링크나 Markdown 표기와 혼동 가능 | 조건 중 2개 이상을 만족해야 합니다: [가독성 개선], [네이밍 명확화], [성능 향상] |
| < > | 꺾쇠괄호 | HTML/XML 태그, 시스템 지시자 | 명령어, API 응답 placeholder | ❌ LLM이 마크업 태그로 인식 가능성 높음 | 응답은 <user_id>, <access_token> 형태입니다. |
| " " | 큰따옴표 | 자연어 강조, 문자열 구분, 지시어 고정 | 코드 지칭, 명확한 용어 설명 | ✅ 가장 안정적인 텍스트 구분자 | "입력 코드"에서 오류를 찾으세요. |
| ( ) | 소괄호 | 부가 설명, 선택 조건 설명 | 부가 설명, 선택 조건 설명 | 정보 보충, 예시 지시어, 조건 명시로 이해 | "입력 코드"(아래 블록 참조)에서 어떤 점을 개선할 수 있는가? |
| // | 파이프 괄호 | 명시적 강조, 커스텀 지시어 구분 | ⚠️ 다중 파이프 사용 시 Markdown 표 형식으로 인식될 수 있음 | 입력 코드 |
기호별 프롬프트
| 기호 | 명칭 | GPT 내부 인식 용도 | 추천 사용 전략 | 주의사항 | 예문 |
|---|---|---|---|---|---|
| $ | 달러 기호 | 변수, 금액, 수학 표현 | 템플릿 변수, API 키, 수식 표현 | 문자열 내 변수처럼 인식 가능 | 코드에서 $username과 $password를 적절히 대체하세요. $API_KEY |
| % | 퍼센트 | 수치 비교, 수식, 확률 | 정확도/비율 설명 시 사용 | 자연어로 percent보다 인식 잘 됨 | 70% 정확도는 기준 이상입니다. |
| * | 별표 | Markdown 강조, 리스트 구분 | 강조, 글머리 기호 | 두 개 ** 이상 사용 시 bold | 강조된 개념과 리스트: 입력, 검사, 출력 |
| - | 하이픈 | 리스트, 마이너스, 구분선 | 항목 나열, 마이너스 값 표현 | 문단 내 연속 사용시 구분선 인식 가능 | 단계별 실행: - 초기화 - 로드 - 검증 |
| @ | 앳 기호 | 유저명, 변수, 경로 지시자 | 이메일, 명령대상 식별자 | @GPT, @user 등으로 다중 객체 지시 가능 | @notification_service는 이벤트 발생 시 자동 호출됩니다. |
예문
아래 "입력 코드"를 참조하고, (리팩토링 대상 함수)에서 개선할 수 있는 점을 말하시오.
또한 다음 조건 중 2개 이상을 만족해야 합니다: [가독성 개선], [네이밍 명확화], [성능 향상]
코드 내 {username}과 $token 값은 환경에 따라 동적으로 치환될 수 있습니다.
출력 형식은 다음과 같습니다:
