


0. 개요 및 시퀀스
- 네이버 의약품 사전(https://terms.naver.com/medicineSearch.naver)
크롤러임.
시퀀스
A. 네이버 의약품 사전에서 약품 검색
B. 해당 약품 이름, url, rating을 수집
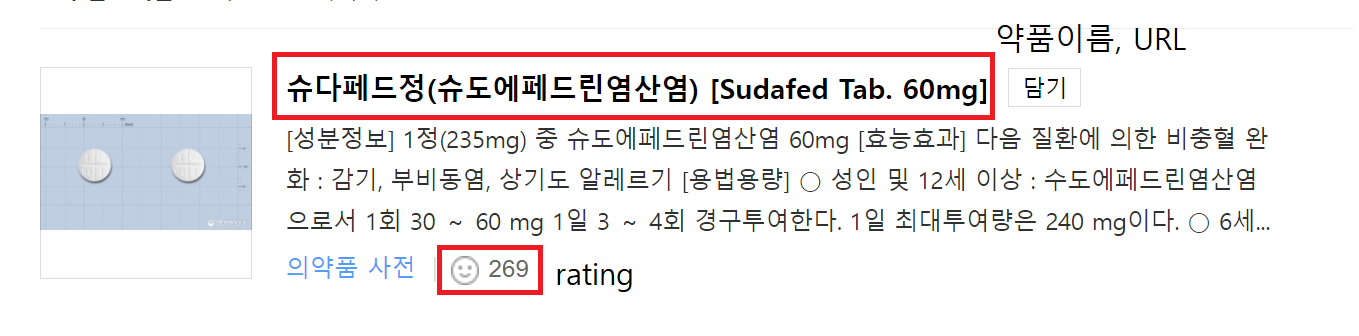
C. Dataframe으로 변환 후 수집 조건에 맞는 url 선정 (ex. rating >=5)
D. target_url을 선정하였으면 각 url을 수집하여 bs4 패키지로 순회하여 크롤링을 진행.
E. 수집 데이터 (성분정보, 효능효과, 용법용량, 저장방법, 사용기간, 사용상의주의사항 등)

| Date | 비고 |
|---|---|
| '24. 1. 13. | 최초 작성 |
1. 사전 준비
1-A. pip install
selenium==4.16.0
bs4==0.0.1
requests==2.31.0
pandas==2.1.41-B. chrome driver
2. 전체 코드
■ 나의 git
아래 코드 해석과 전체 코드가 상이할 수 있음.
3. 코드 해석
3-A. pip
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
import time
import pandas as pd
import requests3-B. 코드 내 사용할 함수 선언
def frist_name(browser, num):
try:
name = browser.find_element(By.XPATH, f'//*[@id="content"]/div[3]/ul/li[{num}]/div/div[1]/strong/a[1]/strong').text
except:
name = 'Nan'
return name
def frist_rating(browser, num):
try:
rating = browser.find_element(By.CSS_SELECTOR, f'#content > div.list_wrap > ul > li:nth-child({num}) > div.info_area > div.related.v2 > div > span:nth-child(2) > div > a > span.u_likeit_text.num._count').text
except:
rating = browser.find_element(By.CSS_SELECTOR, f'#content > div.list_wrap > ul > li:nth-child({num}) > div.info_area > div.related.v2 > div > span:nth-child(2) > div > a > span.u_likeit_text._count').text
return rating
def frist_url(browser, num):
try:
url = browser.find_element(By.XPATH, f'//*[@id="content"]/div[3]/ul/li[{num}]/div/div[1]/strong/a[1]').get_attribute('href')
except:
url = 'Nan'
return url
def page_check(browser):
if browser.find_element(By.XPATH, '//*[@id="paginate"]/span[2]/a').get_attribute('href')[-1] == '#':
return True- 약품이름, URL, rating 수집시 사용되는 함수
frist_name: 약품 이름 수집 함수frist_rating: 약품 rating 수집 함수frist_url: 약품 URL 수집 함수page_check: 마지막 페이지인지 아닌지 확인하는 함수
3-C.
# 검색할 목록이 담겨있는 txt파일 읽기
r = open('pill_list.txt', 'r')
pill_list = [i.rstrip() for i in r.readlines()]
random.shuffle(pill_list)
# 수집한 데이터를 채워넣을 Dataframe
df_url = pd.DataFrame(columns=['이름', 'rating', 'url'])
df_url_idx = 0
# 약품검색 url
url = f'https://terms.naver.com/medicineSearch.naver?mode=nameSearch&query=' #{}&page=13-D. 1차 약품 이름, url, rating 수집
for pill in pill_list[:]:
page = 1
while True:
browser.get(url + pill + '&page=' + str(page))
time.sleep(1.5) # 인터넷 상태에 따라서 조정하여 사용. 너무 짧을 경우 rating이 수집되지 않는 경우가 있음.
# browser.implicitly_wait(1.5)
browser.execute_script("window.scrollTo(0, document.documentElement.scrollHeight);")
for i in range(1, 10+1):
try:
pill_rating = frist_rating(browser, i)
except:
break
pill_name = frist_name(browser, i)
if pill_name in df_url['이름']: continue
pill_url = frist_url(browser, i)
df_url.loc[df_url_idx] = [pill_name, pill_rating, pill_url]
# print([pill_name, pill_rating, pill_url])
df_url_idx += 1
page += 1
if page_check: break # 마지막페이지일 경우 반복 종료
df_url['rating'] = df_url['rating'].apply(lambda x: 0 if x == '' else x)
df_url['rating'] = df_url['rating'].apply(lambda x: 0 if x == '공감' else x)
df_url.to_csv('url_df.csv', encoding='utf-8-sig', index=False)
df_url['rating'] = df_url['rating'].astype(int)3-E. target_url 선정 및 크롤링
target_url = df_url[(df_url['rating']>=5)].reset_index(drop=True)
target_url.drop_duplicates(inplace=True) # 중복값 제거
크롤링 데이터를 저장할 Dataframe
final_df = pd.DataFrame(columns=["이름", "성분정보", "효능효과", "용법용량", "저장방법", "사용기간", "사용상주의사항", 'url'])
final_df_idx = 0
# 실질적인 크롤링 부분
for i in range(len(target_url)):
res = requests.get(target_url.iloc[i,2])
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
temp = soup.find_all('p', {'class': 'txt'})
temp = list(temp)
try:
final_df.loc[final_df_idx] = [target_url.iloc[i,0],
temp[0],
temp[1],
temp[2],
temp[3],
temp[4],
temp[5],
target_url.iloc[i,2]]
final_df_idx += 1
except:
final_df.loc[final_df_idx] = [target_url.iloc[i,0],
"Nan",
temp[0],
temp[1],
temp[2],
temp[3],
temp[4],
# temp[5],
target_url.iloc[i,2]]
final_df_idx += 1
print(target_url.iloc[i,2])3-F. 크롤링 이후 데이터 처리 및 csv 생성
def pre_word(x):
return str(x).replace('<p class="txt">',"").replace('<b>',"").replace('</b>',"").replace("</p>","").rstrip().replace("<br/>","\n").replace(">",">").replace("<","<")
for c in final_df.columns.tolist():
final_df[c] = final_df[c].apply(lambda x: pre_word(x).lstrip().rstrip())
final_df.to_csv('final_df.csv', index=False, encoding='utf-8-sig')pre_word: 크롤링한 내용 중 html 태그를 제거해주는 함수- 왜 bs4.text를 안쓰는가? >> 크롤링 내용이 너무 많아서 중간 중간에 개행처리를 해줘야 하는데 bs4.text는 개행 태그인 <\br>까지 삭제해버림.
4. 부족한점 및 한계
-
크롤링 내용 중 표로 되어있는 부분이 있는데 해당 부분은 크롤링이 상당히 까다로움. >> 이 부분은 표가 있는 url을 따로 추출하여 selenium으로 접근해야함.
-
pre_word 함수 개선이 필요함. <\br> 태그를 개행문자 \n 으로 바꾸고 bs4 패키지에 text를 통해 변경하는게 깔끔할것으로 보임.
-
간헐적으로 오류가 발생함. >> 의약품 사전 페이지 내 html 구조가 조금씩 달라서 생기는 오류로 추정.

어디로 가야하오